
Recently, the growth in demand for skills in data science has grown faster than the skill level of specialists. Today it is difficult to imagine a business that would not benefit from a detailed analysis of the data that scientists and machine learning algorithms conduct. Since artificial intelligence penetrates all corners of the industry, it is difficult to satisfy the needs of data scientists in every possible use case. To reduce the pressure created by this deficit, several companies have begun to develop structures that can partially automate the process commonly used by Scientists.
Automation of Selection of Model Hyperparameters In H2O [Tutorial]
AutoML is a method that automates the process of applying machine learning methods to data. As a rule, a data processing specialist spends most of his time pre-processing, engineering features, selecting and tuning models, and then evaluating the results. AutoML can automate these tasks by providing a basic result, and it can also provide high performance for certain problems and provide an understanding of where to continue your research.
In this article, we will look at the Python H2O module and its AutoML function. H2O is Java-based software for data modeling and general computing. According to H2O.ai, “The main purpose of H2O is a distributed, parallel memory processing mechanism (up to several hundred gigabytes with the Xmx parameter for the JVM).”
AutoML is a feature in H2O that automates the process of building a large number of models in order to find the “best” model without any prior knowledge. AutoML won’t win you in any competition (however, this information is outdated - editor's note), but it can provide a lot of information that will help you create better models and reduce the time spent studying and testing various models.
The current version of AutoML can train and perform cross-validation for random forest, extreme random forest, random mesh of gradient boosting machines, random mesh of deep neural networks, and then train a composite ensemble using all models.
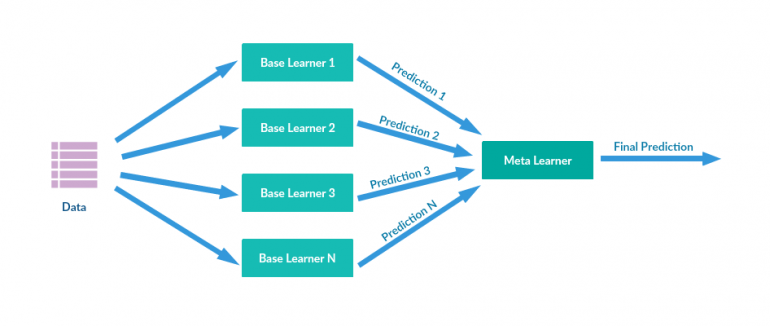
Stacking (also called meta-assembly) is a method of ensemble of models used to combine information from several predictive models to create a new model. Often, a combined model (also called a Level 2 model) is superior to each of the individual models due to its smoothing nature and the ability to highlight each base model where it works best, and weaken each base model where it does not work well. For this reason, stacking is most effective when the underlying models are significantly different.
Prediction stacks of machine learning models often exceed current academic results and are widely used in Kaggle competitions. On the other hand, they usually require large computing resources. But if time and resources are not a problem, then often a minimal percentage improvement in the forecast can, for example, help companies save a lot of money.
Data exploration
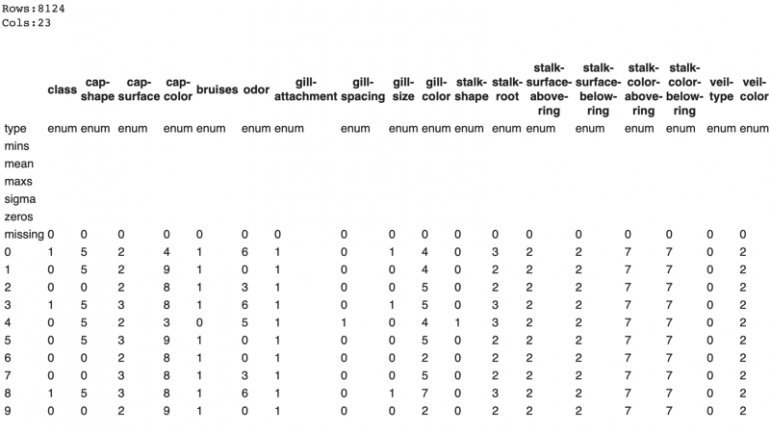
In this article, we will look at the Mushroom Classification Dataset, which can be found on Kaggle and which is provided by UCI Machine Learning. The dataset contains 23 categorical attributes and more than 8000 objects. The data are divided into two categories: edible and toxic. Classes are distributed fairly evenly, with 52% of the objects in the edible class. There are no missing observations in the data. This is a popular dataset with over 570 Kaggle kernels that we can use to see how well AutoML works compared to traditional working methods.
H2O launching
First you need to install and import the Python H2O module and the H2OAutoML class, as in any other library, and initialize the local H2O cluster (for this article I use Google Colab).
import h2o
from h2o.automl import H2OAutoML
h2o.init()
Then we need to load the data, this can be done directly in the “H2OFrame” or (as I will do for this dataset) in the pandas DataFrame, so that we can apply label encoding and then convert them to H2OFrame. Like many things in H2O, an H2OFrame works very similarly to a Pandas DataFrame, but with slight differences and a different syntax.
# Load data into H2O
path = "./gdrive/My Drive/Mushrooms/mushrooms.csv"
# df = h2o.import_file(path=path, header =1)
df = pd.read_csv(path)
labelEncoder = preprocessing.LabelEncoder()
for col in df.columns:
df[col] = labelEncoder.fit_transform(df[col])
df = h2o.H2OFrame(df)
df = df.asfactor()
Although AutoML will do most of the work for us in the initial stages, it’s important that we still have a good understanding of the data we are trying to analyze so that we can build on its work.
df.describe ()
Like the functions in sklearn, we can create a separation between train and test so that we can test the model in an invisible (test) dataset to prevent overfitting. It is important to note that when separating H2O frames, there is no exact separation. It is designed to work with big data using the probabilistic separation method, not the exact separation. For example, if you specify a separation of 0.70 / 0.15, H2O will separate the train / test with the expected value of 0.70 / 0.15, and not the exact 0.70 / 0.15. For small datasets, the sizes of the resulting partitions will differ from the expected value more than for large data, where they will be very close to accurate.
train, test, valid = df.split_frame ( ratios = [ .7 , .15 ])
Then we need to get the column names for the dataset so that we can pass them into the function. There are several parameters in AutoML that must be defined: x, y, training_frame, and validation_frame, of which y and training_frame are mandatory, and the rest are optional. You can also configure values for max_runtime_sec and max_models. max_runtime_sec is a required parameter, and max_model is optional. If you do not pass any parameter, it takes a NULL value by default. Parameter x is the feature vector from training_frame. If you do not want to use all the attributes from the passed frame, you can skip the x parameter.
To solve this problem, we are going to use all the parameters in the x data frame (except the target) and set the value max_runtime_sec to 10 minutes (some of these models take a lot of time). Now it's time to run AutoML:
y = "class"
x_train = train.columns
x_train.remove(y)
aml = H2OAutoML(max_runtime_secs=600, seed = 1)
aml.train(x = x_train, y = y, training_frame = train)
Here, a function was specified for starting a 10-minute training period, but instead it was possible to specify the maximum number of models. If you want to customize the workflow of AutoML, there are also many additional parameters that you can pass for this:
- validation_frame: This parameter is used to early stop individual models in AutoML. This is the data frame that you pass to test the model, or it can be part of the training data if you did not miss it.
- leaderboard_frame: If specified, models will be evaluated according to these values instead of using cross-validation metrics. Again, values are part of the training set if they are not missing by you.
- nfolds: the number of folds in k-fold cross validation. By default, 5 may contribute to a decrease in model performance.
- fold_columns: Specifies the index for cross-validation.
- weights_column: If you want to specify weights for specific columns, you can use this parameter. Assigning a weight of 0 means that you exclude the column.
- ignored_columns: Returns to the x parameter.
- stopping_metric: Indicates the metric for stopping the grid search early. By default, models use logloss for classification and absolute deviation for regression.
- sort_metric: Parameter for sorting leaderboard models. By default, the AUC metric is used for binary classification, mean_per_class_error for multiclass classification, and absolute deviation for regression.
After launching the models, you can see which models work best and consider them for further study.
lb = aml.leaderboard
lb.head()

To make sure that the model has not been retrained, we now run it on test data:
preds = aml.predict(test)
Results
AutoML generated accuracy and F1-score values of 1.0 on the test data, which means the model has not been retrained.
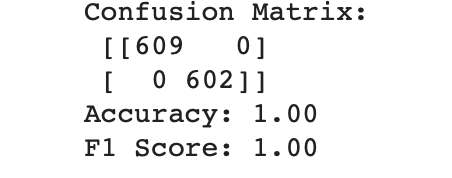
Obviously, this is an exceptional case for AutoML, since we cannot improve accuracy to 100% on our test dataset without testing more data. Looking at many of the kernels presented at Kaggle for this dataset, it seems that many people (and even the Kaggle Kernel bot) were also able to get the same result using traditional machine learning methods.
Follow up work
The next step is to save the trained model. There are two ways to preserve the leader model — the binary format and the MOJO format. If you use your model in production, it is recommended to use the MOJO format, as it is optimized for use in production.
Now that you have found the best model for the data, you can conduct further research on the steps that will improve the performance of the model. Perhaps the best model on the training data is retrained, and another top model is preferable for test data. It may be better to prepare or select only the most important features for some models. Many of the best models in H2O AutoML use ensemble techniques, and perhaps the models used in ensembles can be further developed.
Although AutoML alone won’t bring you superiority in machine learning competitions, it is definitely worth considering as an addition to your mixed and folded models.
AutoML can work with various types of datasets, including binary classification (as shown here), multiclass classification, and also work with regression tasks.
Conclusions

AutoML is a great tool that helps (rather than replace) the work that data scientists do. I look forward to seeing the achievements that can be made in AutoML environments and how they can benefit all of us as scientists and the organizations they serve. Of course, one automated solution cannot exceed human creativity, for example, when it comes to character engineering, but AutoML is a tool worth exploring in your next data analysis project.


X
Thank you for Subscription!
Read more












Let's talk!
Thanks!
We will contact you soon.






