
A 2024 report by Exploding Topics showed that the global generative AI market was valued at approximately $13.71 billion and may soar to $118.06 billion by 2032. Notably, the advertising and marketing sectors have seen an impressive 37% adoption rate.
Among these AI applications, synthetic speech generation is a revolutionary way to transform how your business engages with its users. That said, the effectiveness of a synthetic voice isn’t only dependent on its functional capabilities like accuracy or speed.
Nonfunctional requirements (NFRs) such as scalability, reproducibility, and recoverability are just as important. Let’s see how following these NFRs helps you create an AI voice, add music, and fine-tune your customer interactions to hit all the right notes.
Key Business Challenges in How to AI Generate Voice
A 2022 survey by Boston Consulting Group (BCG) revealed that 95% of global customer service leaders expect their customers to interact with AI bots that have lifelike voices in the next three years.
That isn’t easy to implement, and the underlying technology involves intricate layers of AI and machine learning algorithms working in unison to produce ultra-realistic AI voices and contextually appropriate AI-powered speech.
At Geniusee, we also encountered similar challenges while developing Uberduck (AI voice generator):
Meeting business requirements. A customer service AI must understand and generate human-like responses to reflect your brand's tone and adhere to privacy regulations. Determining these conditions involves extensive collaboration across teams—from data scientists to marketing professionals—to ensure the final product aligns with your business objectives and user expectations.
Our approach at Geniusee involved a dual strategy of comprehensive needs analysis and modular system architecture development. They ensured Uberduck’s voice synthesizer could be easily customized to meet the industry’s specific demands and offer a personalized experience.
Perceived simplicity versus actual complexity. A primary challenge is that the users interact with services that respond with human-like voices, leaving them unaware of the complex processes running in the background, like text-to-speech conversions and AI-generated voices.
Our solution was to adopt an agile development methodology that embraced continuous feedback and rapid iterations, helping us create tailored speech tools that adapt dynamically to user and client needs to present better and optimized audio files.
Keeping up with technical and ethical policies. AI voices and audio processing technologies also involve a complex ethical policy. Proactively address data privacy, security, and potential misuse with AI voice cloning to maintain the balance between innovation and practicality.
Our team developed Uberduck by continually refining data usage policies and creating secure frameworks to protect the technology's users, target voice, and integrity.
Understanding these challenges helps craft robust and user-centric solutions as we explore new possibilities within synthetic speech generation. We also propose creating an infographic that outlines the key steps in adopting AI voice technologies.
These would include stages from initial concept and needs analysis to integration and live deployment, providing a clear roadmap for businesses considering similar initiatives.
3 Nonfunctional Requirements in Synthetic Speech Generation
Nonfunctional requirements are not technicalities but are central to the success and sustainability of these systems.
At Geniusee, we focus on three critical nonfunctional requirements: scalability, reproducibility, and recoverability. Each plays a unique role in ensuring our voice generation AI technology is robust, reliable, and ready for the demands of the modern market.
1. Scalability
Scalability ensures your technology can handle increasing workloads without compromising performance or efficiency, which is crucial when your Artificial Intelligence system serves more users or processes larger text-to-speech datasets.
As demand grows, your speech generation system should match user needs and seasonal spikes without running into costly overhauls. Using AI with a horizontal and vertical scaling approach, you can effectively use auto-scaling and load-balancing techniques to your advantage.
For example, we used cloud-based architectures to add servers or resources as needed without downtime. They doubled our handling capacity within minutes, ensuring everything operated seamlessly. |
2. Reproducibility
Reproducibility refers to the ability to consistently repeat operations and produce the same output, regardless of the number of times, ensuring your platform’s user experience remains consistent across different sessions and interactions.
We created Uberduck to use standardized testing environments and rigorous version control protocols to ensure every system update or change maintains the integrity of the audio samples and audio clips with various voice profiles.
Automate your deployment pipelines to replicate settings and production environments, minimizing human error and output variability. You can then test the service before full-scale deployment, helping you identify and fix any inconsistencies in the performance or output of the audio formats. |
3. Recoverability
Recoverability is crucial for maintaining service continuity during system failures, data loss, or other unforeseen disruptions. It ensures AI tools are restored quickly to normal operations with minimal user impact.
The approach we recommend for recoverability includes comprehensive disaster recovery planning and data protection strategies. You can make an AI voice generative speech system with robust disaster recovery solutions, including regular backups and failover mechanisms to secondary systems.
For example, if your primary data center faces an outage, your system automatically switches to a geographically separate backup center with minimal downtime. We also used data protection strategies like encryption and access controls to safeguard Uberduck against data breaches and ensure the service was back up and running within minutes. |

More from our blog:
Best Automatic Machine Learning (AutoML) Frameworks in 2024
If you need to speed up processes and allow specialists to focus on the most important tasks, you should use AutoML frameworks.
Read nowStrategic Implications of Synthetic Speech Generation Across Organizations
How to make an AI voice is the question that hundreds of businesses have, and rightfully so. AI voices are a strategic asset for businesses looking to differentiate themselves in a crowded marketplace by improving customer engagement, streamlining operations, and expanding market reach.
Improving customer experience. For example, you can make an AI voice to provide dynamic product recommendations and tailored shopping advice with customer service chatbots. They help improve customer satisfaction rates and increase repeat purchases by 15%.
Streamline operations. For example, a services firm used synthetic speech to automate its call center operations, reducing call handling time by 30% and significantly cutting operational costs.
Expanding market reach. For example, an e-learning platform integrated voice clips with synthetic speech to make marketing videos and offer courses in over 20 languages, doubling its user base and penetrating markets in regions previously inaccessible due to language barriers.
How to Make AI-Generated Voices
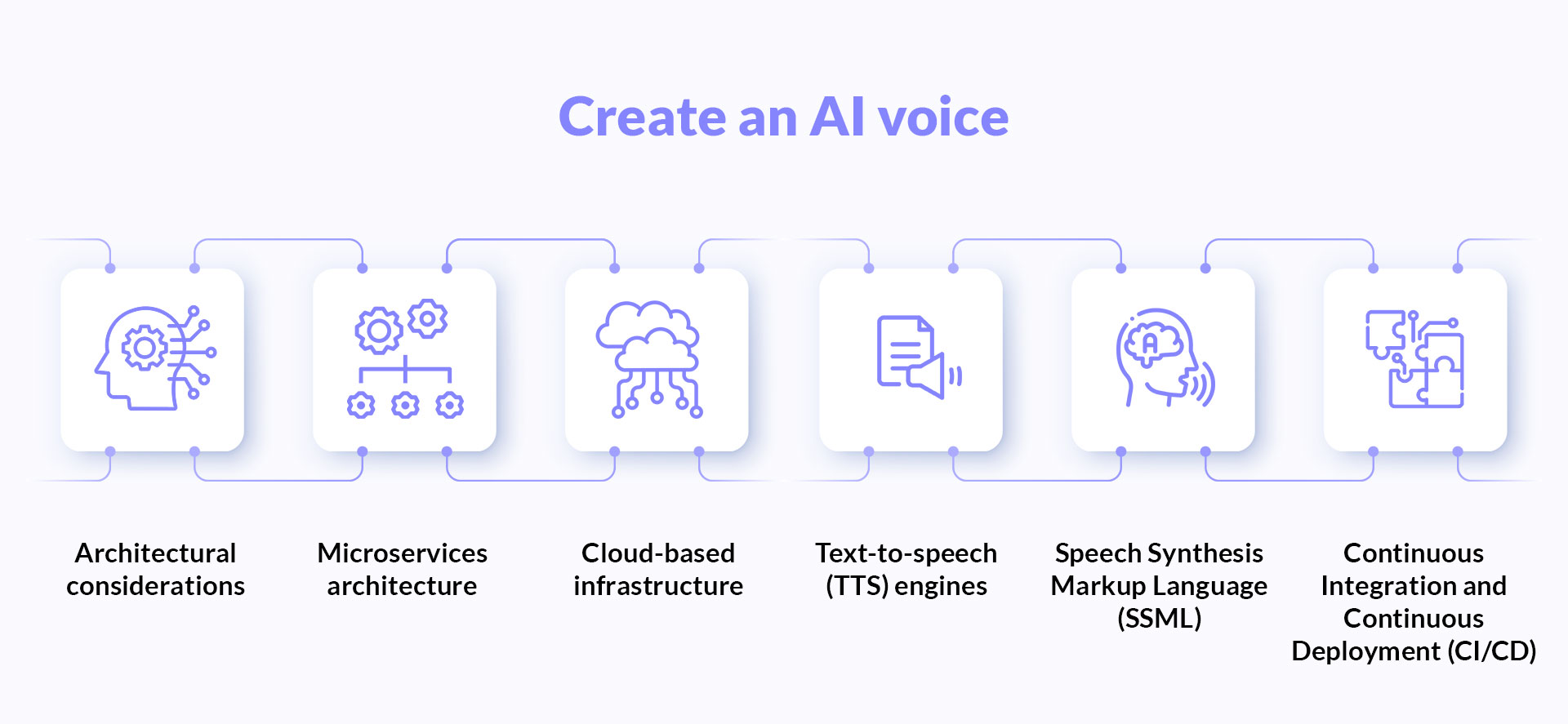
So, if you are also considering how to create an AI voice to mimic human speech, keep these points in mind.
Architectural considerations. A well-designed architecture ensures the system can handle varying loads and expand to accommodate growth without degradation in performance.
Microservices architecture. It involves decomposing the application into minor, interconnected services that perform specific functions. This modularity allows for easier scaling because each service can be scaled independently based on demand.
Cloud-based infrastructure. Cloud platforms typically offer built-in scalability options, such as auto-scaling and elastic load balancing, which can dynamically adjust resources based on real-time demand.
Text-to-speech (TTS) engines. These engines convert written text into spoken words. Advanced TTS engines use deep learning algorithms, such as recurrent neural networks (RNNs) or transformers, capable of understanding and generating human-like speech by learning from large datasets of spoken audio.
Speech Synthesis Markup Language (SSML). It can add pauses, emphasize specific words, control pitch, and manage speech rate to improve naturalness and produce expressive speech. Implementing SSML allows you to fine-tune the speech output of your voice clone to meet specific user needs.
Continuous Integration and Continuous Deployment (CI/CD). Implementing CI/CD pipelines in the development process ensures changes to the codebase are automatically tested and deployed in a controlled and systematic manner. It supports reproducibility by maintaining consistency in deployment practices and helps quickly roll back changes if something goes wrong.


Thank you for Subscription!
The Impact of Synthetic Voices Speech Technology on Businesses
Deploying AI voices delivers substantial benefits across various business operations. These include:
Increased operational efficiency. Reduced average handling times and increased automated query resolution using voice clones can significantly reduce call center workloads for telecommunications providers.
Enhanced customer experience. Implementation led to an improvement in customer satisfaction scores for online retailers, thanks to real-time, human-voice synthetic speech responses.
Scalability and market expansion. Enables e-commerce platforms to extend services into multiple non-English speaking markets, boosting global market share.
Innovation and competitive advantage. Health technology companies that introduce voice-responsive health monitoring systems increase sales and distinguish their product in the market.
Streamlining internal communications. Organizations that adopt synthetic speech for training purposes report increased training engagement and improved employee knowledge retention.
Wrapping Up
If you’re still wondering how to make AI audio, the process isn’t easy. However, following the main points and requirements will help you overcome the issues.
These generative AI tools can have a profound impact on your business operations. From enhancing customer service to streamlining internal communications, synthetic speech offers many benefits that help businesses stay competitive.
Here’s a quick recap of the article.
Strategic value. Computer-generated voice systems provide strategic advantages by improving customer interactions, increasing operational efficiency, and enhancing accessibility and inclusivity.
Business challenges and solutions. Although implementing a wide range of custom voice solutions comes with challenges, such as complexity in development and the need for continuous updates, Geniusee helps you successfully navigate these issues by focusing on scalability, reproducibility, and recoverability.
Technical insights. Building robust voice clone synthetic speech systems involves careful consideration of architecture, algorithms, and methodologies. Emphasizing nonfunctional requirements such as scalability and recoverability ensures these systems are practical and durable.
Quantitative and qualitative benefits. Making a voice using synthetic speech technology has led to quantifiable improvements in customer service efficiency and engagement rates and qualitative enhancements in user experience.
Increased naturalness and expressivity. As AI models become more sophisticated, the naturalness and expressivity of synthetic speech will continue to improve, making interactions almost indistinguishable from those with humans.
Greater integration with emerging technologies. Synthetic speech will increasingly be integrated with other AI technologies, such as emotion recognition and predictive analytics, to provide more responsive and personalized user experiences.
Expansion into new markets. As the technology becomes more accessible and cost-effective, we can expect its adoption across a broader range of industries, including healthcare, education, and public services, where it can aid accessibility and learning.
Ethical and regulatory developments. With the growth of synthetic speech, ethical and regulatory considerations will become more prominent. Issues around data privacy with voice cloning, security, and the ethical use of AI-generated voices and audio content will require clear guidelines and standards.




















