
AI adoption is booming across industries, backed by bold budgets and huge expectations. But as systems move from pilots to production, many teams discover the same thing: costs grow faster than impact.
What looked promising in a demo becomes unpredictable at scale, and month by month, the gap between investment and return gets harder to ignore.
So let’s break down why this cost spiral happens, how to reasonably reduce costs, and how to build smarter, leaner, and more sustainable AI products.
What causes AI costs to spiral out of control?
Most companies don’t struggle with AI ROI because their teams are careless or because 'artificial intelligence is not for them.' They overspend because they’re using outdated approaches to manage a fundamentally new kind of system.
The old way of thinking, inherited from traditional software development, assumes that you can separate R&D, infrastructure, and product into neat boxes. Each team manages its part, and cost control happens through budget reviews, vendor management, and quarterly check-ins.
But AI-powered models aren’t self-contained—they rely on interconnected data pipelines, shared compute, continuous retraining, and ongoing monitoring. A model built by one team may generate infrastructure costs for another, require compliance reviews from a third, and need updates based on product shifts that no one originally accounted for.
This plays off regardless of whether you're building a FinTech, EdTech project, or an AI in any other niche.
Here’s how that plays out in practice:
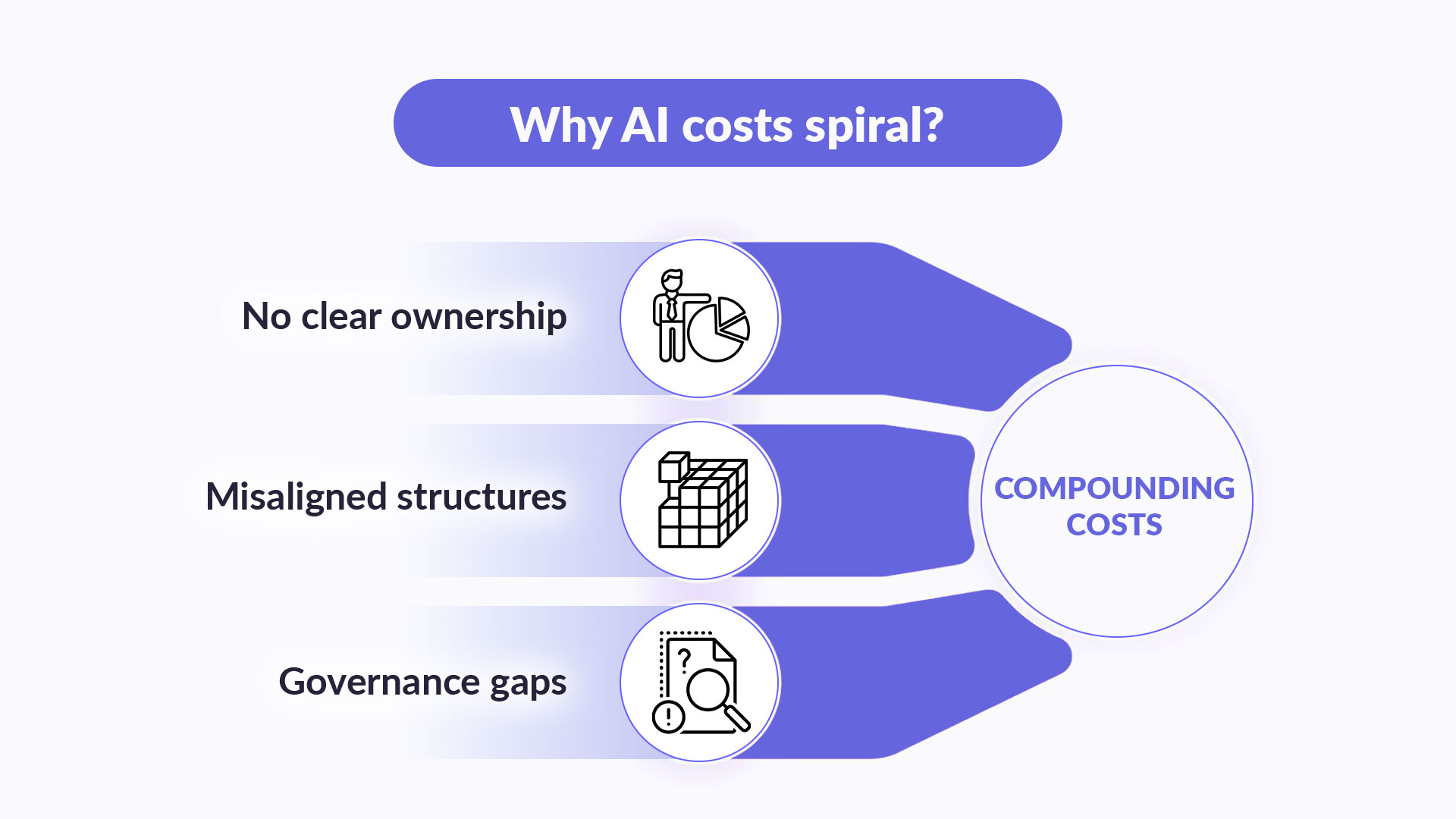
No clear ownership. No one owns AI initiatives across the full lifecycle, and because different teams each handle only their part, costs accumulate across handoffs with no one responsible for optimizing the whole.
Misaligned structures and responsibilities. AI responsibility is split across functions, but budgets and goals remain siloed, so teams make disconnected decisions that lead to duplications, which also increases costs.
Governance gaps and unaccounted complexity. As auditability, explainability, retention, and traceability requirements increase, operational overhead rises, but because compliance costs aren’t tracked per model, they disappear into baseline spend while manual processes and regulatory drag keep growing.
Misplaced focus on AI over business value. Teams often prioritize building or scaling AI systems without a clear link to measurable outcomes. Instead of optimizing for impact, they optimize for technical novelty, leading to overengineered models, unused features, and inflated infrastructure spend with no proportional business return.
To understand how deep the waste goes, let's zoom in on the lifecycle itself and see where exactly money is being lost.
Where does the money leak? The lifecycle view of AI waste
The real trap isn't the high cost itself. It’s the belief that cost equals progress.
It isn’t so hard to find waste once you start looking closely. When you do, you’ll see small but deeply compounding inefficiencies baked into how AI systems turn into financial black holes.
And each stage of the lifecycle carries its hidden cost centers.
Data and Labeling
Most AI teams are sitting on training data workflows that were never designed for reuse or cost-efficiency. This results in:
Redundant data pipelines with high-volume, cross-infrastructure transfers
Huge data transfer between infrastructure that introduces additional cost
Over-reliance on manual labeling
No use of synthetic data or weak supervision
No embedding or feature reuse across tasks
Storage of unused, outdated, or duplicate datasets
Embedding reuse without drift validation
Which, in turn, leads to silent duplication of effort, inflated labeling costs, and a slow buildup of technical debt across the stack—all before a model is even trained. And once it is, it won’t rise above the mess it came from because your model is only as good as your data.
Model Training
Training is one of the most visible costs in AI, and despite that, most of the waste tends to be normalized.
And here's how it goes:
Overparameterized models trained far beyond what’s needed
Expensive generative AI LLM models (e.g., GPT-4 from ChatGPT) fine-tuned for tasks solvable by smaller OSS models
No profiling done before training
No version control or machine learning model governance
This leads to runaway training bills, oversized models no one can maintain, and a pileup of barely-used checkpoints with no traceable rationale.
Inference and Serving
Deployment often gets less attention than training, but it’s where long-term costs add up fast, especially when infrastructure is treated as a one-size-fits-all problem.
Some of the typical cases are:
Models always kept on, even when usage is low
Teams defaulting to overpowered infrastructure (e.g., GPU for everything)
Cost-latency trade-offs and cloud cost implications are not being evaluated
Lack of quantization and pruning to reduce inference cost and model size
No load balancing or dynamic autoscaling in place
This results in GPU resources burning quietly in the background, latency gains no one asked for, and serving stacks that scale up but never down.
Monitoring and Retraining
Monitoring is critical, but without discipline, it turns into its own AI cost center, especially when retraining cycles aren’t tied to actual model decay or business value.
And here's what we mean:
Excessive and unfocused monitoring
Manual root cause analysis
No automated decay detection, especially critical in generative AI
No cost monitoring or actual focus on cost reduction
The result is bloated workflows that drain engineers’ time, retraining cycles that burn GPU hours without measurable ROI.
Even the most advanced AI stack can quietly bleed money if its foundations aren’t built with cost-awareness in mind. What looks like progress at each stage often hides inefficiencies that, left unchecked, silently erode impact and scalability.


Thank you for Subscription!
How to fix the leak: Three proven AI cost optimization strategies
Cost reduction in AI isn’t about tightening screws in every silo or asking teams to be more cautious. Each part might be perfectly optimized in isolation and still fail to solve the problem.
Cost-efficiency has to be designed into how AI is developed, deployed, and owned from the ground up. The following cost management roadmap shows where to start.
1. Make AI costs visible across the lifecycle
Goal: To create transparency into spending, usage, and ownership over AI.
The biggest cost leaks in AI don’t come from mistakes—they come from a lack of visibility. Without clear ownership or cost signals at each step, small inefficiencies compound and stay hidden.
Start by mapping the system:
List all active models, pipelines, and datasets.
Tag each one with its owner, business purpose, infrastructure type, training data source, and how often it gets updated.
Then tie infrastructure spend to actual use cases:
Track training compute costs
Measure inference spend and cloud cost at production scale
Attribute storage usage (both live and archival)
Include monitoring, logging, and alerting systems
Next, embed that visibility into the workflows where real decisions happen:
Integrate into CI/CD pipelines
Include in deployment approvals
Add to model review documentation
Surface in shared dashboards used by product, infra, and machine learning teams
And finally, integrate FinOps tools directly into those flows to surface cost data in real time:
AWS CUDOS for usage breakdowns
GCP Billing Export for tagging and attribution
BigQuery for custom cost analysis and dashboards
Once this is in place, your team stops guessing. You’ll know what’s worth retraining, what’s worth archiving, and what’s just quietly burning budget in the background.
2. Apply systemic controls and structural fixes
Goal: To move from reactive cost control to embedded cost ownership across layers.
Visibility helps you see the problem, but structure is what actually fixes it. Without it, teams build in silos, overengineer by default, and create systems that quietly bleed time, budget, and sanity.
To reverse that, start with infrastructure alignment. Instead of letting each team build their own stack:
Centralize deployment, monitoring, and inference environments
Standardize orchestration layers, pipelines, and vector DBs
Eliminate low-ROI tooling that increases complexity without unique value
Then bring discipline to decision-making with enforceable controls:
Set internal cost-performance benchmarks for models and pipelines
Define kill criteria for models that underperform or overcost
Run regular ROI audits—not only for new launches but also for what’s already running
Involve product and infrastructure leads at the architecture stage, not at cleanup
To avoid overengineering, match your governance approach to your growth stage:
Early stage: keep it lightweight, emphasize reuse, lean coordination, and just-in-time reviews
Growth: introduce structure, design checkpoints, and shared accountability
Enterprise: formalize design reviews, cost thresholds, and cross-team oversight
To reduce duplicate effort and cut unnecessary retraining, hard-code reuse into your workflows:
Share base models, pipelines, and embeddings across teams
Use adapters or prompt engineering before retraining large models
Treat reused components like production assets by:
Versioning embeddings that are reused across tasks
Validating each reused component (e.g., a prompt or data set) for its specific use case
Monitoring for drift, especially in NLP and recommender systems
To avoid GPU bloat and scale inefficiencies, build trade-offs into the design from day one:
Apply quantization, distillation, and profiling before scaling
Route workloads intelligently across CPU and GPU
Accept small accuracy trade-offs for major infra savings
To avoid vendor lock-in or hidden overhead, compare tools by total lifecycle effort, not just unit price:
Calculating cost-per-token relative to performance for large language models
Measuring latency and throughput trade-offs for vendor APIs
Evaluating OSS versus commercial tools by factoring in support, tuning, and maintenance overhead
Once structural fixes are in place, cost-efficiency stops being a firefight. Teams stop duplicating effort, infrastructure becomes reusable by default, and every new AI decision carries a built-in check on its long-term value.

More from our blog
AI in wealth management: how to win the market
Learn how AI is reshaping wealth management, how firms are responding, and how your company can stay ahead.
Read more3. Build for compounding value at lower cost
Goal: To turn short-term cost savings into long-term leverage by investing in architectural reuse, automation, and smart experimentation.
The final layer of AI cost optimization isn’t just about saving more—it’s about making every dollar work harder.
Too many AI teams reuse components, but not in a way that compounds. Instead, they rebuild similar pipelines, retrain models that solve the same problem, or run isolated experiments that don’t feed the system as a whole.
The result? Progress that looks fast in the short term but doesn’t scale. If every success is a one-off, you’re paying full price every time.
To change that, start by building architectural leverage:
Build shared modules for retraining, evaluation, augmentation, and routing
Automate what’s still manual: cost anomaly detection, drift monitoring, retraining triggers
Treat infrastructure usage like a live metric, not a quarterly report
Then embed governance before anything ships:
Assign a clear owner to every model
Require cost transparency before launch
Enforce a reuse check before retraining
Replace long-running POCs with short, ROI-tied pilots:
Measure success not just by performance but by total cost and repeatability
Train engineers to optimize for efficiency as well as accuracy
Frame every experiment in terms of what it delivered and what it cost to deliver
If you want to optimize costs in AI, the goal isn’t just to spend less—it’s to get more from what you already spend. That means designing systems that compound value: through shared infrastructure, enforced reuse, and clear cost accountability. Once it's achieved, cost-efficiency stops being reactive and starts becoming a built-in advantage.
AI cost optimization framework
Visibility | Structural fixes | Compounding leverage |
|
|
|
This three-level approach helps AI teams design lean, efficient, and scalable systems, whether they're building or fixing what's already running.
How Genuisee helps you optimise AI costs
Cost efficiency doesn’t just depend on the right ideas — it depends on how you build.
At Geniusee, we work with teams at every stage, from early design to long-term scaling. Whether you’re launching a first use case or untangling a complex architecture, we combine deep technical delivery with practical advice to make sure cost-awareness is built into your system.
Here’s how we can help:
Audit existing systems for inefficiencies. We run structured reviews of current models, pipelines, and infrastructure to surface redundant costs and low-ROI tooling.
Match business needs with the right-sized tech. We help you select architectures and models that fit the actual use case, not what’s overbuilt or unnecessary.
Design reusable, lean AI architecture. We build standardized pipelines and encourage system-wide reuse of models and components to reduce duplicated work.
Support custom vs. open-source cost-benefit assessments. We assess OSS and commercial tools based on lifecycle cost, maintenance, and long-term fit.
And also, develop full AI systems with cost-efficiency built in. From initial design to implementation, we handle end-to-end development using scalable, maintainable practices.
Whether you're overbuilding, overspending, or overwhelmed, we help you go lean, without losing capability.
Wrapping up: what scaling AI actually requires
Long-term efficiency in AI doesn’t come from individual optimizations—it comes from designing systems that stay cost-aware as they grow.
That means:
Making costs visible across the full lifecycle, from training to deployment and monitoring.
Embedding reuse, ownership, and cost-performance trade-offs into the way teams build and ship.
Using architecture and governance to reduce duplication, avoid waste, and make scaling predictable.
At Geniusee, we support this with both advisory and development. Whether you’re refining an existing system or building a new one, we help you align architecture, tools, and processes around sustainable, cost-efficient growth.




















