
As our industry gets older and there are more outdated applications, we are increasingly faced with the problem of legacy code when it is impossible to use the latest features of our favorite framework. We will analogy a house of cards to convey how neat, thoughtful, and painstaking work with outdated technologies must be.

This is what the legacy code looks like. If we decide to remove or replace at least one card from this building, we risk filling up the entire house and razing its remains to the ground.
In this article, I want to look at a more general option for working with old or poorly performing systems. I want to answer the questions: What is a legacy code? Signs of legacy code. Risks of working with legacy code. What to do if you need to work with a legacy system?
In general, inherited does not mean bad by default. There is legacy software with excellent architecture, documentation, etc. In this article, inherited will have a negative connotation. I will talk about architecture problems, lousy code, the definition of legacy code, and lack of tests and documentation. In these systems, there are many things such as "it happened so historically," "it's better not to touch it," outdated frameworks and development approaches, programming languages , and DBMS.
In This Article:
Legacy Code Definition
Legacy code means code that has been "inherited" from previous developers. Simply put, legacy is a code about which they say: "Dan wrote this eight years ago to synchronize with the server, it works, we don't touch it, because otherwise, everything will break." At the same time, Dan has not been in the company for a long time, there is no documentation either, and it's easier not to touch this code.
Since legacy is old code, many essential things in the program are usually tied to it. It turns out to be a vicious circle: you can't refuse legacy because, without it, everything will break, but it's also challenging to maintain it in working order because no one wants to understand the old code.
Key features for legacy systems
- Implemented on old technologies and platforms.
- Outdated approaches to development, design, and architecture are used.
- No unit and integration tests. Maybe it's impossible to write unit tests with the current design?
- The system is difficult to make changes. It breaks in unexpected places. In general, there may be poor code quality.
- Wrong unreadable code with many smells, sometimes it is not clear why it works.
- Routine operations are not automated, which periodically leads to potential errors and increases the bus factor.
- No system and infrastructure documentation.
There is a feeling that a project with such characteristics will not please you day after day. More likely to become your headache.
Popular scenarios of how systems become legacy
- Development began many years ago. During this time, the development team implemented many different functions. The teams have entirely changed several times. Other parts of the system are written in different styles. Such a system is of great value to the customer. Perhaps the system is a little unstable, but it is not so critical for the customer.
- Software engineers developed the system quickly, but a team was with low technical competence. The code is overgrown with technical debt and is very fragile. The system has almost stopped its development and is waiting for a hero to carry out the correct refactoring. As in the previous paragraph, changes in the design will be complicated because it is already used in work.
- The development of the first version was unsuccessful (for example, the team failed), the system was not launched. Now you need to draw conclusions from the first failure and implement everything as expected.
- Your current system, which used to be so small and clean, is turning into a terrible monster that is out of control. We need to break the situation and make it manageable.
Challenges of Working With Legacy Code
Legacy is not some kind of crime but a part of the life of any living IT company. Sooner or later, any product will have a legacy. And the bigger the project, the bigger it will be. For example, in the Windows 10 source code, there are still pieces of code written 20 years ago for Windows 3.1. Let's take a closer look at the challenges we face while working with legacy software.
- Legacy systems are often essential to the customer. These systems are already being used; they are already making money, so errors in the code can be very expensive.
- If the system has already been launched, users have learned to work with it, to bypass its problems. For example, you probably heard in stores: "Now the system is frozen, you have to wait a bit, then restart the computer, then I will pay again. It's okay. It happens." Your new implementation may be better, but don't forget about user retraining.
- Knowledge about the history of the legacy system may be lost, so you risk forgetting to implement the functionality that was in the old system.
- Or just break what's already working. For example, we recently refactored a large system, it was uploaded to several identical servers to balance the load. As it turned out, only one of them had the parameter in the configuration file changed, which started one of the services. There was no information about this anywhere. A month later, we learned it by accident from a developer from the previous team.
- Due to problems in the code, you may not be able to deliver new features by the planned date.
- Usually, the work is under the pressure of deadlines and many technical debts, which threatens to lose motivation in the team.
- There will be a slowdown in development for some time because you will be part of the project. We need to make sure that the customer is ready for this.
Suppose, after evaluating all the risks, you agreed to take on the job. At this point, you need to understand an important thing. There will be no division for the customer into "our code" and "not our code." The code is now all yours, and you work with it. Are you having unexpected problems in an incredible place? Now, this is your problem. Are you not to blame? The code was brittle, and that's why everything broke? For the customer, now you are responsible for the code, and you solve all the problems. Get ready to search, debug, profile a legacy system for a significant amount of time.
I would recommend working with legacy systems by Time & Materials in terms of contract terms. It will partially reduce your risks. Working for a fixed price and volume can be dangerous because legacy systems hold many surprises. There is a risk of making a big mistake by misestimating the amount of work.
Legacy System Analysis
Before starting work, you need to understand what has already been implemented and how it works. The current functionality needs to be studied, measured and described so that metrics and flags will not worsen it in the future. If possible, you should remove any losses associated with routine operations.
1. Where is the source code located?
You need to take control of changes in the system's source code and all subsystems. I would recommend keeping track of all branches in all repositories that you can access. It will avoid the side effects of the previous command or its remnants that will work with you.
If there is no version control system (don't laugh, this is a common situation), it must be started at the very beginning, even before the first changes in the code. This will allow you:
- Control all the changes that will come from your team and possibly from the remnants of the old team.
- Collect all source codes of the system and all subsystems in one place.
2. Where is the system deployed?
Most likely, you will know little about the infrastructure of the system. You will need to audit servers, security policies, domain settings, backup settings, etc. It is quite a complex and painstaking job for a system administrator. I would recommend taking care of access to servers in advance because you may have to get special permissions, recover logins/passwords, or look for "the one who remembers the password."
If you have up-to-date infrastructure documentation, then this is a great success. In any case, it is worth bringing the system administrator up to date and giving him the task of updating the documentation.
3. What version is currently running?
When the system has already begun to be used, you need to understand which version is currently uploaded to the servers. The version number must be uniquely comparable to the revision number in the version control system. This will come in handy when studying the system's operation, analyzing its behavior, debugging, and profiling.
The usual situation is that they cannot tell you exactly which version of the assemblies is currently uploaded and where to find the code. Then we move on to the next step and set up the release of new versions ourselves.
4. How to release a new version?
You should automate the release of a new version of the system and any part of it. Ideally, you should access the CI server and ensure that new versions are released with the click of a button.
Often there is no CI in projects. You need to schedule time with the customer and set up CI in this case. In your release version, you should include at least:
- 1 - Building the latest versions of all projects in the system.
- 2 - Putting the current version number.
- 3 - Modifying configuration files for the environment.
- 4 - Running automated tests.
- 5 - Releasing Artifacts for Pouring.
We have looked through the minimum set of steps that will allow you to remove most of the routine mistakes and save time in the future. Plus, you will learn how to assemble a new project for yourself, which is not so easy for several reasons.
5. Is the system integrated with other systems?
Before you make any changes to the legacy system, you need to get integration schemes with third-party projects. Perhaps the system uploads something or takes it from third-party FTP; it has public web services, uploads to accounting systems, etc.
As long as there is no documentation, the information must be collected and documented on your own, then given to the customer and its developers for review. After all, you don't want contractors to call the customer after uploading your version and ask where their data has gone? Minor changes in the system can break developed over the years, but a fragile scheme of integration with subsystems of the company and third-party clients.
It is worth checking whether there is integration with third-party services such as Google Webmaster, maps, etc. As an example, I can cite a system that we recently urgently completed. After uploading, one of the customer's teams lost about a million pages from the Google index. They made several changes to the system's architecture and weren't convinced that the integration with Google worked correctly.
If you were provided with documentation about all integration points, it must be updated.

6. Job logging
You will need constant feedback on new bugs that occur. It is obtained through a logging system running on combat servers.
Providing there is no logging system,this system must be deployed before making changes to the code. If this system exists, but the logs just lie on the servers, you have to set up notifications to your mail. It is desirable to fasten a system like elmah to make it easier to process logs from all servers.
You don't have to be afraid of being bombarded with mistakes. You want the situation in the system "as is," and the error stream you'll see will:
- Open the customer's eyes to the actual situation on the project.
- Give you extra motivation to get things right as soon as possible.
7. Are monitoring and analytics configured?
In complex systems, a third-party analyzer is usually made, which periodically sends reports with the results of the system. These can be reports on the dynamics of registrations in the system, purchasing activity analysis, the completeness and integrity of data, and others. If something like this already exists in the legacy system, it is worth subscribing to all notifications and giving your quality control department access to them.
8. Unit and integration tests
Once the project has unit or integration tests, this is an excellent opportunity to study the scenarios of the system. First, you need to run all the tests and delete empty or useless ones to not hang with technical debt. There are tests written to increase code coverage. It is also better to remove them at the very beginning. There may be tests in the project that are commented out or marked with the [Skip] attribute sometimes; examining them can reveal problems in the project.
Green tests will be your best friends because they are the most up-to-date documentation for the system. Existing tests must be included in CI if they haven't already. If the code is without tests, you can spend some time on Characterization Testing. This will allow you to understand the behavior of the system better.
On condition that there are no tests, you will want to cover the code with tests. Here you can face several problems:
- 1 - The customer does not allocate time to cover the code with tests. Then QA must do a full manual testing of the system and double-check the regression before each release.
- 2 - You cannot write unit tests due to errors in system design. In this case, it is undesirable to throw all your efforts into refactoring the system and gradually covering the code with tests because this process can be delayed. If there is a lack of experience, it can be unsuccessful.
9. Where can you find test scripts?
Before making changes, the entire system must be tested. QA will definitely be asked about test scripts and documentation in order to do a full test of the current version. You will also need to access the bug tracker to update the known list of bugs and issues.
Suppose there are no test scenarios and the documentation is outdated. In that case, it is advisable to recommend to the customer complete testing of the system and the preparation of test scenarios. This is necessary to fix existing bugs and, in the future, to do regression testing.
10. What were the requirements for the system?
Throughout the development of a legacy system, a number of requirements were placed on it. It is advisable to find all documents/letters/pages in the project's wiki where these requirements are written. In them, you can find answers to questions:
- maximum web interface response time under normal load;
- maximum web interface response time at peak load;
- expected System Load;
- backup frequency.
If the requirements are not formalized, it is advisable to clarify them with the customer and issue them in the appropriate documents. If you found these documents, then I would recommend updating them. Obviously, you need to know the list of system requirements before you start making the first changes. The QA team must analyze the system and clarify which requirements are currently being met and which are not. In the future, QA should constantly check the system for compliance with these requirements and fix improvements or deterioration in the situation.
General Tips for Getting Started
1. You can run it through various analytics and visualization tools to analyze the code. After the analysis, the most critical errors can be corrected, which the tools will reveal if the customer allocates time for this. There are quite a few problems at the beginning of work on a legacy system, so these metrics will not play a decisive role. They will show that everything is terrible with reports of hundreds of errors, but what will it give? You already knew that there were many problems with the project. As development progresses, these tools will become more and more in demand.
2. The customer can offer a technical lead from his side. It is pretty good practice, but you have to be careful. If this tech lead was involved in developing an unsuccessful version that failed, they could continue implementing erroneous ideas in your team. Agree that it is difficult to recognize your creation as terrible. We made such a mistake, for which we paid with 4 months of fighting the stereotypes that have developed on the project.
3. Despite this, taking a developer from the previous team who is on the project as a consultant is a good idea. You will come up with solutions that the previous team has already tried and failed for a number of project-specific reasons. This knowledge about the project's development will be useful in the future.
4. In addition to numerical metrics, you will need people able to understand that the system is getting better or worse. Most likely, it will be someone from those departments support, analysts, the customer himself or one of the key (or group) users. Use every opportunity to fix the current state of the system so that you can make a comparison with each change.
5. It is necessary to collect and enter all technologies, frameworks, OS, DBMS, etc., in the table that is used in the system. View their versions, highlight those no longer supported and make an upgrade plan. These are somewhat tricky and lengthy changes, so it is unlikely that the customer will allow you to do this at the beginning of your work, but it will be helpful to have this information.
6. In case you do not have a test server (staging, UAT) in the system, it is advisable to deploy it at the very beginning. This can be a time-consuming task due to the complexity of the project infrastructure or the large amount of data required to run the system.
7. If you do not understand where to move initially, you can split into several teams, each of which will follow its path of development. Thus, you can quickly develop the necessary solutions.
Code Rewriting Strategy
After working through the above questions, you should understand what kind of system you got and what condition it is in. Now we need to figure out how to move on.
A set of specific tactics has already been described in various books:
- Refactoring. Improving Existing Testing Code by Martin Fowler,
- Refactoring with Templates, Joshua Kerievsky,
- Working Effectively with Legacy Code, Michael K. Feathers.
These books provide specific examples and answers to code improvement and test coverage questions. For example, what to do with a long method that is difficult to test? How to break unnecessary dependencies? How to remove dependency on static class? And much more. I recommend reading these books and 90% of the problems in the code will not be a problem for you.

I propose considering the main strategies that can be used when working with legacy systems.
1. Rewrite
You look at someone else's code, and you see a lot of flaws in it. I just want to write it right from scratch. Why not? One of the possible options for developing the old system is its rebirth in a greenfield project.
Pros:
- By analyzing the inherited code, we learn how not to do.
- The system will certainly contain many good solutions that can be taken. This will save time when creating a project from scratch.
- Increased motivation in the team because the codebase will be completely "yours."
Cons:
- The customer will pay for the creation of the same system for the second time.
- The customer will not see the difference between what it was and how it became for a long time. The first release of the new system, which will surpass the old system in terms of the number of features, will not appear soon.
- If the system is already in use, then rewriting old functions can take a significant amount of time.
- You will have to support both the old and new systems at the same time until all users migrate to the new one.
- The system may turn out to be more complicated than you initially thought; there is a chance to make it as bad as it was or worse. You do not know all the system's nuances and subsystems that have accumulated over the years.
Recommendation when it is worth taking on rewriting the entire system from scratch:
- The customer gives time and money to rewrite the old system from scratch, and you, for your part, are confident in your abilities.
- The system has not yet started to be used. Perhaps it is a prototype or 'proof of concept.'
- The system really does not work, and users refuse it. For example, we had a project that the previous team wrote for a year. In the end, it simply did not meet the declared characteristics. There was no point in adding or refactoring code. We analyzed what was done wrong and implemented a new version from scratch, taking into account previous errors.
2. Leave it as it was
You can decide not to touch what is already written. Write new code in the same style, do not refactor, do not change the system's design. Perhaps the system is too large and complex, the deadlines are pressing, there is no budget for fixing critical bugs, or maybe the code seemed good enough to you. Then you adopt the standards and approaches from the current implementation.
Pros:
- Work on the system does not stop, and the client sees the results of his investments.
- Delivering new features and fixing bugs from the very beginning of your work.
Cons:
- The customer may insist on not wasting time on an abstract design improvement but simply fixing a couple of critical bugs. If the code in the system is terrible, then you add even more crutches there and try to get rid of this project as soon as possible.
- There is a chance to get into the situation described by Brooks: "All corrections tend to destroy the structure, increase the entropy and disorganize the system. Less effort is spent on correcting the errors of the original project and more and more on eliminating the consequences of previous corrections."
- Resuscitation of the system is many times more difficult than creating a new one. This job requires high qualifications.
- There is a chance to waste the time of the developers and eventually roll back all the changes.
Suggestions for when to leave things as they are:
- The business does not need new features. It only needs to fix some of the existing ones. This happens when further development of the system is not planned. Perhaps a new system is being created in parallel, with new ideas on a new platform.
- It is necessary to quickly give a result , even by deliberately adding crutches to the modern code. I understand that this can aggravate the situation, but if the customer makes a huge profit from this breakthrough, then in the future, he will be able to invest it in other strategies for working with the legacy system.
- The code is good enough, and there are tests, the architecture meets the requirements of the client.
3. New app around the old one
This approach is a toned-down version of a complete system rewrite from scratch. We are building a new application around the old one. As the new application grows, it takes over more and more existing system functions. At the same time, we do not touch the old system, and we write new functions in the new one.
The metaphor was described by M. Fowler in the article Strangler Application.
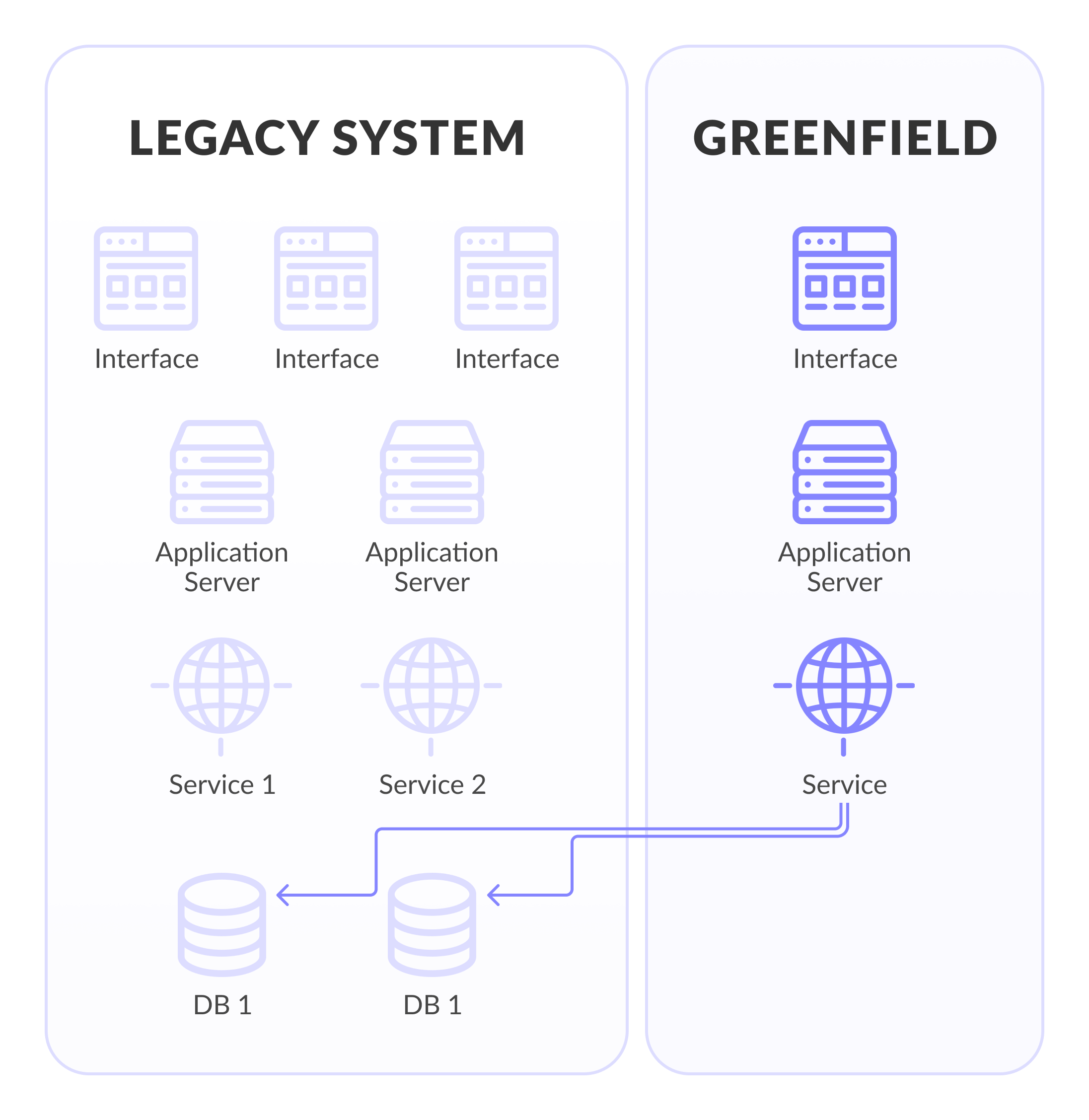
Pros:
All the advantages of the first approach with a complete rewrite.
The work of the old system does not stop, and at the same time we add new features.
The customer immediately begins to see the results of their investments.
If the legacy system is built on Event Sourcing or with a common bus, then the implementation of event interception will be straightforward.
Cons:
Supposing there were serious errors in the system, we would have to fix them in the legacy code.
There is a danger of not completing (for example, funding will end or stop working with the customer), then the system will become an even bigger monster with two heads.
With a complex and intricate legacy system architecture, this approach can be difficult to implement.
In my opinion, this is one of the most difficult approaches that requires a good preliminary analysis and a high level of software developers.
Suggestions when to use this method:
A legacy system is stable.
Basically, you need to add new features and not expand existing ones.
4. Processing by modules
If it is not possible to create a new application around the old one and it is impossible to leave the code in the current state, then we can only do gradual refactoring code and improve the design of the system. To do this, release by release, we isolate parts of the system, isolate independent modules, and rewrite them. Thus, most of the system will be rewritten after a certain time.

Pros:
- Gradual improvement of system quality.
- The ability to make a constant delivery speed, not the highest, but stable.
- Users continue to work with an already familiar system, receiving periodic updates.
Cons:
- There will be no sharp jump in the quality of the system; perhaps the development speed will be too low for the customer.
- It is not always possible to select modules.
Recommendation when it is worth gradually rewriting by modules:
- A legacy system has high customer value.
- The system has many debugged modules.
- Basically, you need to expand existing functions.
Tools for Working Effectively With Legacy Code
One of the most promising code quality tools for updating legacy systems is Robotic Process Automation (RPA) technologies. Customer needs, competition, and the market are constantly evolving, and the only way to keep up with this rhythm is to use modern technology.
With the help of RPA, you can gradually transform legacy systems. The main function is to automate manual and repetitive tasks performed according to an algorithm. In addition, robotic automation is more flexible, faster, and cheaper than many others. Deloitte's global survey found that RPA met or exceeded the expectations of 85% of respondents. RPA solutions are already widespread and are only getting more efficient, making them a very reliable way to upgrade legacy systems.
Three main advantages of using RPA for legacy systems
1. Rapid implementation. With RPA, there is no need for coding or other complex software; this allows integrators to implement RPA solutions more efficiently and quickly while maintaining a high level of productivity.
2. Low implementation costs. RPA tools do not require significant material or human resources, which distinguishes the technology from similar tools on the market. Low costs allow system integrators to scale faster and be flexible when planning budgets.
3. No security issues. RPA provides maximum security for system integrators and IT departments by allowing them to control access authorization and manage sensitive data.
How Geniusee can Help with Legacy Code
There are billions of lines of legacy code in the world right now, and their number is increasing every day. The Geniusee team is responsible for the quality of the code because other developers, including our client's team, also work with our code. That is why we are trying to solve the problem of legacy code by educating our employees about the causes of inherited code and improving the developer education system.
What do we do with existing legacy code? We are gradually improving the code instead of completely replacing it. This requires investment in the skills to develop and apply modern practices. We believe that the only way to grow better code is to grow brilliant people. This is the theme of lean thinking.
Conclusion
In this article, we've covered mostly technical issues when dealing with legacy systems. Technical changes alone will not be enough for long-term success. For example, the introduction of CI or Continuous Deployment fundamentally changes the very approaches that were on the project.
For the success of the project, you need to change the development culture, instill new values in the product owners and users, remove all waste, and automate the routine.
Geniusee team has experience dealing with the outdated code base. We were able to throw away bad code and rewrite everything from scratch. If you encounter problems with legacy code, you can order a static code analysis of your system and a plan for its redesign from us. Look at our software development expertise and fill out the contact us form below, may our Geniusee dedicated team become your dream team.




















