From the very beginning of the computer age, developers have been trying to teach them to understand ordinary languages, for example, English. For thousands of years, people wrote something, and it would be great to instruct machines to read and parse all this data.
Unfortunately, computers cannot fully understand living human language, but they are capable of much. NLP can do truly magical things and save a huge amount of time.
The process of reading and understanding the English text is very complicated. In addition, people often do not follow the logic and sequence of narration. For example, what does this news headline mean?
"Environmental regulators grill business owner over illegal coal fires".
Do regulators interrogate business owners about illegal coal-burning? Or maybe they literally cook it on the grill? Did you guess? Whether a computer can?
The implementation of a complex task with machine learning usually means building a pipeline. The point of this approach is to break the problem into very small parts and solve them separately. By combining several of these models that deliver data to each other, you can get great results.
Let's take a look at the following excerpt from Wikipedia:
“London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south-east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.”
This section contains some useful facts. I wish the computer could understand that London is a city, it’s located in England, was founded by the Romans, etc. But first of all, we must teach it the most basic concepts of written language.
- Step 1
Highlighting sentences
The first stage of the pipeline is to break the text into separate sentences. As a result, we get the following:
- London is the capital and most populous city of England and the United Kingdom.
- Standing on the River Thames in the south-east of the island of Great Britain, London has been a major settlement for two millennia.
- It was founded by the Romans, who named it Londinium.
It can be assumed that each sentence is an independent thought or idea. It’s easier to teach a program to understand a single sentence, not a whole paragraph.
One could simply separate the text according to certain punctuation marks. But modern NLP pipelines have more sophisticated methods in store, suitable even for working with unformatted fragments.
- Step 2
Tokenization, or word highlighting
Now we can process the received offers one by one. Let's start with the first one:
London is the capital and most populous city of England and the United Kingdom.
The next step of the pipeline is the allocation of individual words or tokens - tokenization. The result at this stage looks like this:
«London», «is», «the», «capital», «and», «most», «populous», «city», «of», «England», «and», «the», «United», «Kingdom», « . »
In English, this is easy. We simply separate a piece of the text each time we encounter a space. Punctuation marks are also tokens, as they can be important.
- Step 3
Definition of parts of speech
Now let's look at each token and try to guess what part of speech it is: a noun, a verb, an adjective or something else. Knowing the role of each word in a sentence, we can understand its general meaning.
At this step, we will analyze each word together with its immediate environment using a previously prepared classification model:
This model has been trained on millions of English sentences with already indicated parts of speech for each word and is now able to recognize them.
Keep in mind that this analysis is based on statistics - in fact, the model does not understand the meaning of the words. It just knows how to guess a part of speech based on a similar sentence structure and previously studied tokens.
After processing, we get the following result:
- London
Proper Noun
- Is
Verb
- The
Article
- Capital
Noun
- And...
Conjunction
- Step 4
Lemmatization
In English and most other languages, words can take many forms. Take a look at the following example:
I had a pony. / I had two ponies.
Both sentences contain the noun “pony”, but with different endings. If the computer processes the texts, it must know the basic form of each word in order to understand that we are talking about the same concept of a pony. Otherwise, the pony and ponies tokens will be perceived as completely different.
In NLP, this process is called lemmatization - finding the basic form (lemma) of each word in a sentence.
This is what our offer looks like after processing:
- London
Proper Noun
- Is
To be
Verb
- The
Article
- Capital
Noun
- And...
Conjunction
The only change is turning “is” into “be”.
- Step 5
Defining Stop Words
Now we want to determine the importance of each word in a sentence. There are a lot of auxiliary words in English, for example, “and”, “the”, “a”. In a statistical analysis of the text, these tokens create a lot of noise, as they appear more often than others. Some NLP pipelines mark them as stop words and filter them out before counting.
Now our sentence is as follows:
- London
Proper Noun
- Is
To be
Verb
- The
Article
- Capital
Noun
- And...
Conjunction
Ready-made tables are usually used to detect stop words. However, there is no single standard list suitable in any situation. Ignored tokens can change, it all depends on the features of the project.
For example, if you decide to create a rock band search engine, you probably won't ignore the article “the”. It is found in the name of many collectives, and one famous group of the 80s is even called “The The!”.
- Step 6
Parsing dependencies
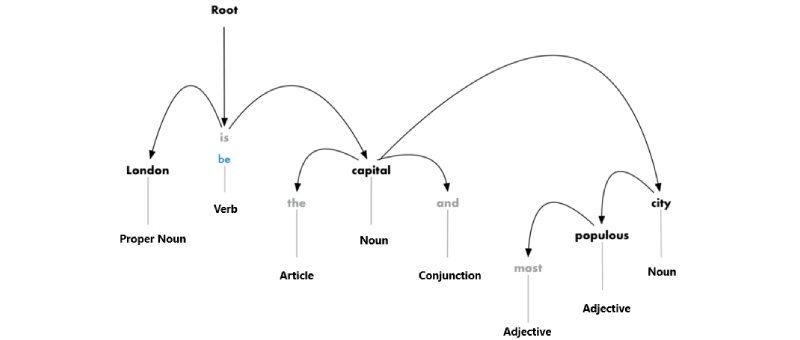
Now you need to establish the relationship between the words in the sentence. This is called dependency parsing. The ultimate goal of this step is to build a tree in which each token has a single parent. The root may be the main verb.
After the first approach, we have the following scheme:
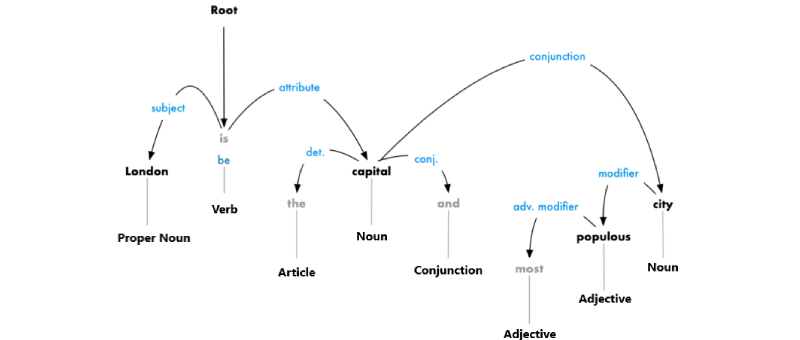
It is necessary not only to determine the parent but also to establish the type of connection between two words:
This parsing tree demonstrates that the main subject of the proposal is the noun “London”. Between it and "capital", there is a relationship "be". This is how we learn that London is the capital! If we went further up the tree branches (already beyond the borders of the diagram), we could find out that London is the capital of the United Kingdom.
- Step 7
Named Entity Recognition, NER
We have already done all the difficult work. Finally, we can move from school grammar to really interesting tasks.
Our sentence contains the following nouns:
London is the capital and most populous city of England ...
Some of them mean real things. For example, “London” and “England” are points on the map. It would be great to define them! With NLP, we can automatically get a list of real objects mentioned in the document.
The purpose of recognizing named entities is to discover such nouns and relate them to real concepts. After processing each token with the NER-model, our sentence will look like this:
London (geographical name) is the capital and most populous city of England (geographical name)...
NER systems don't just browse dictionaries. They analyze the context of the token in the proposal and use statistical models to guess which object it represents. Good NER systems can distinguish actress Brooklyn Decker from the city of Brooklyn.
Most NER models recognize the following types of objects:
- Names of people
- Company names
- Geographical designations (both physical and political)
- Products
- Dates and time
- Amount of money
- Events
Since these models make it easy to extract structured data from solid text, they are very actively used in various fields. This is one of the easiest ways to take advantage of the NLP pipeline.
- Step 8
Resolving coreference
We already have an excellent and useful presentation of the analyzed sentence. We know how words are related to each other, which parts of speech they refer to, and what named objects stand for.
Nevertheless, we have a big problem. English has a lot of pronouns - words like he, she, it. These are abbreviations by which we replace the real names in writing. A person can trace the relationship of these words from sentence to sentence, based on context. But the NLP model does not know what pronouns mean, because it considers only one sentence at a time.
Let's look at the third sentence in our document:
It was founded by the Romans, who named it Londinium.
If we pass it through the conveyor, we will find out that “it” was founded by the Romans. Not very useful knowledge, right?
You will easily guess in the process of reading that “it” is nothing but London. The permission of coreference is the tracking of pronouns in sentences in order to select all words related to one entity.
Here is the result of processing the document for the word "London":
By combining this technique with a parsing tree and information about named entities, we get the opportunity to extract a huge amount of useful data from the document.
Resolving coreference is one of the most difficult steps in our pipeline, it is even more complicated than parsing sentences. In the field of deep learning methods for its implementation have already appeared, they are quite accurate, but still not perfect.
So we learned a little about NLP!